
Le Big Data apparaît aujourd’hui comme une continuité logique et une évolution naturelle du décisionnel. Après avoir rappelé dans un précédent article les limites de la loi de Moore, cet article présente les solutions technologiques du Big Data. C’est le troisième d’une série de trois sur le thème « De la BI au Big Data ».

De nouvelles solutions technologiques pour répondre aux 3V du Big Data
Si la gestion d’une volumétrie importante est le premier défi du Big Data, ce n’est pas le seul.
Plus globalement, les solutions technologiques du Big Data visent à répondre aux limitations des architectures classiques suivant trois axes, les fameux 3V (Volume, Vitesse, Variété) :
- V comme Volume : Comme nous l’avons vu, la gestion d’une volumétrie importante nécessite d’imaginer de nouvelles architectures pour obtenir des performances acceptables et compenser les limites physiques des débits disques.
- V comme Vitesse : L’arrivée à maturité des objets connectés, des capteurs intelligents, capable de délivrer de la donnée en continu, impose de repenser l’intégration de données en mode batch pour passer sur du temps réel, un aspect souvent très mal et très peu couvert par les solutions traditionnelles.
- V comme Variété : Enfin, les sociétés envisagent de plus en plus d’utiliser de l’information non structurée, en provenance de documents mais aussi et surtout des réseaux sociaux (Twitter, Facebook, LinkedIn, autres réseaux spécialisés). Pour la première fois, il est en effet possible d’évaluer à grande échelle et très rapidement, la valeur ajoutée d’un produit ou encore la pertinence d’une publicité à partir des consommateurs eux-mêmes. C’est une mine d’informations à très forte valeur ajoutée qui nécessite de savoir exploiter des informations textuelles dans des formats variés et non prévisibles.
Panorama des solutions technologiques du Big Data
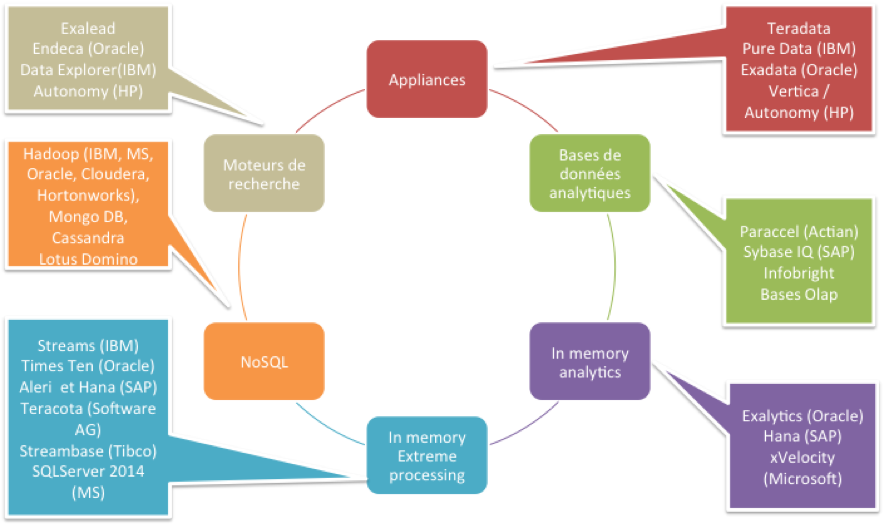
Panorama des solutions technologiques
La première idée a consisté à réduire la volumétrie gérée.
Les bases de données analytiques
Les bases de données analytiques appelées également bases colonnes ont introduit un mode de stockage novateur en « colonne » (versus en ligne pour des bases de données classiques). Cette approche présente un avantage intéressant pour le décisionnel : un mode de compression efficace quand les données en colonne se ressemblent, ce qui est le cas des modèles décisionnels en étoile. Pour une requête donnée, la volumétrie à récupérer sur les disques diminue ce qui améliore de fait les performances en restitution. C’est essentiellement vrai dans un cadre décisionnel (requête sur un ou deux indicateurs et des millions de lignes).
En contrepartie, on peut constater une dégradation des performances en alimentation et sur des restitutions de type « ligne » (une dizaine d’indicateurs et des millions de lignes). Par ailleurs, cette approche logicielle repousse les limites mais ne présente pas de garantie en termes de scalabilité. Une approche totalement différente consiste à miser sur la mémoire.
Les solutions technologiques de type « In memory analytics »
Les solutions technologiques de type « In memory analytics » visent à monter toutes les données en mémoire vive au détriment du disque dont le rôle sera cantonné à assurer la persistance des données. Cette approche radicale est prometteuse et garantie des temps de réponse à la hauteur des attentes. A contrario, le coût d’acquisition de ces plateformes pour les volumétries actuelles est élevé et il est difficile encore de se projeter sur les volumétries à venir.
Les appliances
Pour sortir des limitations évoquées, les éditeurs misent aujourd’hui sur les appliances, des solutions tout en un intégrant le matériel, le stockage et le logiciel pour faciliter l’administration et l’exploitation de la plateforme. La performance est assurée par une architecture massivement parallèle, s’appuyant généralement sur du matériel haut de gamme (réseau infiniband, disques rapides SSD) et intégrant également les avancées logicielles des bases colonnes. Ces solutions sont par ailleurs fortement scalables et présentent un haut niveau de disponibilité avec des composants qui sont tous redondés.
Le développement du NoSQL
Certains acteurs du monde de l’internet (Google, Yahoo, Facebook, Linkedin, etc.) ont été confrontés plus tôt que les autres à ces problèmes de volumétrie. Les données traitées sont par ailleurs variées, des données numériques, des commentaires textuels, des documents, des vidéos ou encore des photos. Ils sont à l’origine du développement du NoSQL (Not Only SQL, solutions pas seulement SQL) basé sur une architecture massivement parallèle construite sur du matériel classique peu onéreux.
Le NoSQL regroupe aujourd’hui en fait une multitude d’initiatives et de projets, en évolution rapide, et qui s’appuient principalement sur le framework Hadoop d’Apache. Hadoop propose par son design une très forte tolérance aux pannes et une excellente scalabilité dans un contexte de traitements batchs. Mais il ne garantit pas pour l’instant de bons temps de réponse et semble donc peu adapté aux traitements interactifs. Les deux dernières familles de solutions qui complètent notre panorama sont plus exotiques. Elles pourraient cependant prendre de l’importance dans l’avenir.
On trouve ainsi les solutions technologiques de type moteur de recherche qui exploitent de manière efficace les données textuelles des documents mais aussi en provenance des réseaux sociaux par exemple.
On trouve également des outils de traitements des données en temps réel (In memory extreme processing), un aspect peu ou mal couvert par les solutions traditionnelles. Ce type de solutions présente de nombreux avantages, pour réguler en temps réel les transports, pour alerter et prévenir des patients équipés de capteurs ou pour analyser en temps réel des données de vidéo surveillance afin d’améliorer la détection d’infraction.
S’il existe des zones de recouvrement, on peut parier que les entreprises associeront bientôt dans leur architecture Big Data plusieurs de ces solutions pour répondre aux enjeux métiers de demain.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Commentaires (2)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
Je suis en phase avec cette segmentation ;-).
Deux remarques :
- on parle ici de la gestion des données, mais il y a d'autres solutions à prendre en compte que ce soit en amont (intégration de données), au dessous (gouvernance de données, data quality...) ou en aval (data discovery et analyse prédictive). J'aime bien cette segmentation de l'analyste Ray Wang pour l'illustrer, même si elle est un peu complexe ( https://goo.gl/cCEbKS ).
- Concernant Hadoop, de mon point de vue, ce slide considère Hadoop 1, avec les environnements Map Reduce et Hbase. Depuis, il y a eu Hadoop 2.0, qui couvre aussi les autres dimensions, que ce soit l'analytique vis SQL (Impala, Tez, etc.), l'in-memory (Spark), le streaming en temps réel (Storm), etc. Il existe des appliances, et surtout une offre dans le cloud qui amène de nouvelles perspectives. J'ai d'ailleurs fait un slide sur le sujet à l'occasion de notre séminaire commun à Bordeaux et Toulouse. Même si certaines de ces évolutions sont encore jeunes, cela montre la capacité d'Hadoop à couvrir de manière large les besoins du Big Data, et aussi l’intérêt du modèle Open Source en termes d'innovation.
Oui, effectivement, la situation est un peu plus complexe aujourd'hui. J'ai privilégié une approche simple qui présente l'avantage de pouvoir faire le lien avec des technologies plus classiques.
Et en plus, je savais que ça te plairait ;)
L'éco-système Hadoop avec Storm et Spark occupe aujourd'hui une place beaucoup plus large et plus centrale. J'ai d'ailleurs prévu de présenter dans un prochain billet les initiatives concernant le SQL sur Hadoop. D'autres articles suivront pour aborder les autres composantes d'un projet Big Data comme l'intégration de données ou les appliances Hadoop.