
Si comme moi vous avez lu de nombreux articles d’introduction ou de stratégie sur le Big Data, vous avez peut-être envie d’une approche plus concrète. Ce tutoriel se propose de vous montrer comment développer un programme MapReduce très simple pour analyser des données stockées sur HDFS.
Tutoriel : Développer un programme MapReduce sur une VM Hadoop
Nous allons reprendre les choses au début avec un traitement « bas niveau » directement sur MapReduce.
Même si on ne rentre pas dans ces détails de développement sur un vrai projet Big Data, cela nous permettra de bien comprendre la mécanique structurelle des traitements sur Hadoop.
Ce tutoriel s’appuie sur une VM mise à disposition par une distribution open-source.
Nous prendrons ensuite des données fournies par le site GitHub afin d’analyser des températures et calculer les maximales par année.
Pour cela votre portable suffit (avec de préférence 8 Go de mémoire).
Si vous souhaitez aller plus loin, vous pourrez lire le guide « HADOOP – The Definitive Guide – 4th Edition » de Tom White, qui m’a très largement inspiré.

Installation d’une VM Hadoop
Vous aurez besoin d’une VM pour ce suivre ce tutoriel.
Pour ma part, j’ai choisi celle de Cloudera, que vous pouvez télécharger avec le lien suivant : QuickStart VMs for CDH 5.4.x .

Pour compléter la mise en place, je vous propose les paramétrages suivants :
- user « cloudera » (répertoire /home/cloudera),
- répertoire partagé avec le host, afin d’y installer les exemples :
mount -t vmhgfs .host:/ /home/cloudera/shares (avec le user root), - installation des exemples du Guide dans le répertoire
home/cloudera/shares/samples/hadoop-book-master
à partir du site web GitHub Hadoop Book (bouton « Download ZIP »), - variables d’environnement :
export HADOOP_HOME=/usr/lib/hadoop,
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin.
Les (presque) Big Data

Il nous faut maintenant copier des fichiers de données dans hdfs :
- le fichier hadoop-book-master/input/ncdc/sample.txt dans le répertoire input/ncdc,
- les fichiers hadoop-book-master/input/ncdc/all/1901.gz et 1902.gz dans le répertoire input/ncdc/all.
Les commandes Hadoop à utiliser pour cela sont les suivantes :
hadoop fs -mkdir -p répertoire
hadoop fs -copyFromLocal fichiers_sources répertoire_cible
hadoop fs -ls répertoire
hadoop fs -cat fichier
Et voilà, vous êtes prêt à analyser les relevés des stations météo pour obtenir les températures maximales par année.
Commençons avec Python

Vous allez écrire vous-même le programme MapReduce en découpant les 2 phases map et reduce.
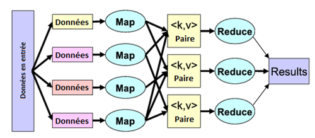
Ils pourront être testés d’abord hors Hadoop en utilisant des pipes Unix, puis dans Hadoop en utilisant le « streaming ».
max_temperature_map.py
Pour chaque ligne de notre fichier source, on extrait l’année, la température et le code qualité d’après leurs positions.
Si les données sont valides, on renvoie l’année et la température séparées par une tabulation.
#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
val = line.strip()
(year, temp, q) = (val[15:19], val[87:92], val[92:93])
if (temp != "+9999" and re.match("[01459]", q)):
print "%s\t%s" % (year, temp)
Testons ce programme hors Hadoop :
cat sample.txt | ./max_temperature_map.py (ajuster les répertoires)
Voici le fichier source :
0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999 0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999 0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999 0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999 0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999
Et le résultat obtenu :
1950 +0000 1950 +0022 1950 -0011 1949 +0111 1949 +0078
max_temperature_reduce.py
Pour chaque ligne renvoyée par le programme map, on extrait l’année et la température.
Pour chaque année, on recherche la température maximale et on renvoie ces 2 informations séparées par une tabulation.
#!/usr/bin/env python
import sys
(last_key, max_val) = (None, -sys.maxint)
for line in sys.stdin:
(key, val) = line.strip().split("\t")
if last_key and last_key != key:
print "%s\t%s" % (last_key, max_val)
(last_key, max_val) = (key, int(val))
else:
(last_key, max_val) = (key, max(max_val, int(val)))
if last_key:
print "%s\t%s" % (last_key, max_val)
Test hors Hadoop
Testons maintenant ces 2 programmes, toujours hors Hadoop :
cat sample.txt | ./max_temperature_map.py | sort | ./max_temperature_reduce.py
Voici donc notre résultat final (température maximale par année) :
1949 111 1950 22
Exécution sur Hadoop
La fonction Hadoop Streaming permet d’interfacer Hadoop avec des programmes écrits dans un langage qui lit et écrit sur les entrées standards d’Unix, par exemple Python.
Il nous faut lancer la commande suivante :
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming-*.jar \ -input input/ncdc/sample.txt \ -output output \ -mapper /home/cloudera/shares/samples/max_temperature_map.py \ -reducer /home/cloudera/shares/samples/max_temperature_reduce.py
Vous noterez qu’il n’y a pas de fonction de tri, le framework Hadoop s’en charge.
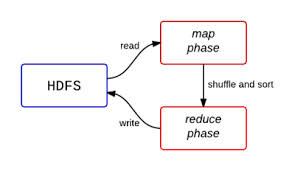
Le résultat est dans le répertoire output sous HDFS :
hadoop fs -ls output
-rw-r--r-- 1 cloudera cloudera 0 2015-06-23 11:19 output/_SUCCESS -rw-r--r-- 1 cloudera cloudera 17 2015-06-23 11:19 output/part-00000
hadoop fs -cat output/part-00000
1949 111 1950 22
Essayons maintenant en Java

Pas de panique, les exemples téléchargés précédemment contiennent tous les éléments pour réaliser notre programme MapReduce en Java.
Le code source se cache dans le répertoire hadoop-book-master/ch02-mr-intro/src/main/java, le tout est déjà compilé et packagé dans hadoop-book-master/hadoop-examples.jar.
Il ne vous reste qu’à lancer l’exécution :
- cd /home/cloudera/shares/samples/hadoop-book-master
- export HADOOP_CLASSPATH=hadoop-examples.jar
- hadoop fs -rm -r output
- hadoop MaxTemperature input/ncdc/sample.txt output
Sans surprise, nous obtenons le même résultat qu’en Python :
1949 111 1950 22
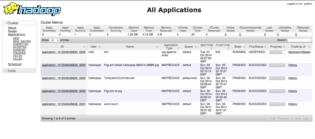
Suivi des traitements
Hadoop fournit une interface Web pour le suivi les traitements. Nous allons nous en servir pour suivre notre traitement MapReduce.
Pour y accéder dans la VM Cloudera, le lien est https://quickstart.cloudera:8088/cluster :
Si ce tutoriel vous a intéressé, vous pouvez poursuivre avec cet article « Spécial Tutoriels ».








![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)





Commentaire (1)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.