
A la suite du tutoriel MapReduce basé sur la VM Cloudera, ce nouveau tutoriel vous propose de poursuivre l’exploration concrète des outils Big Data à travers la mise en œuvre de la Data Platform d’Hortonworks.
A la découverte de la Data Platform d’Hortonworks
Les exemples d’utilisation porteront sur le comptage de mots dans un texte, des statistiques de baseball et l’analyse de weblogs.
Installation d’Hortonworks
Pour commencer, nous allons télécharger la VM fournie par Hortonworks à l’adresse suivante :
https://fr.hortonworks.com/products/hortonworks-sandbox/#install.
Vous retrouverez également sur ce site de nombreux tutoriels fournis par Hortonworks.
Cette figure positionne ainsi les différents composants de la plateforme Hortonworks :
Nous allons successivement utiliser dans ce tutoriel les composants HDFS, MapReduce, Hive, Pig et HCatalog.
Accès en mode commande
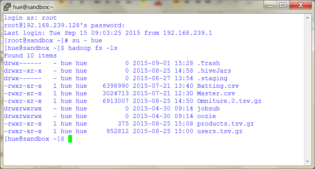
L’accès en mode commande se fait via putty en mode ssh, à l’adresse 192.168.239.128.
Les codes utilisateurs sont root / hadoop et hue / 1111.
Accès par navigateur Internet
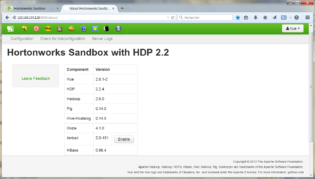
Dans votre navigateur Internet, entrez l’adresse https://192.168.239.128:8000/about/.
Vous avez ainsi accès aux différents outils qui seront utilisés dans ce tutoriel.
MapReduce
Nous commençons ici encore par le plus basique, à savoir l’accès aux données stockées sur HDFS en mode programmatique.
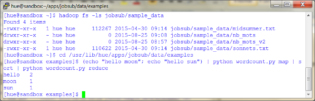
Dans la fenêtre ssh, on localise 2 fichiers texte, midsummer.txt et sonnets.txt, sur lesquels nous allons effectuer des comptages de mots :
- hadoop fs -ls jobsub/sample_data
Un 1er test permet de valider le bon fonctionnement du programme Python wordcount hors hadoop :
- cd /usr/lib/hue/apps/jobsub/data/examples
- (echo « hello moon »; echo « hello sun ») | python wordcount.py map | sort | python wordcount.py reduce
Puis sur un de nos fichiers d’exemples :
- (hadoop fs -cat jobsub/sample_data/sonnets.txt) | python wordcount.py map | sort | python wordcount.py reduce
Nous pouvons passer maintenant à une exécution en streaming sous hadoop :
- hadoop jar /usr/hdp/2.2.4.2-2/hadoop-mapreduce/hadoop-streaming.jar \
-input jobsub/sample_data/midsummer.txt -output jobsub/sample_data/nb_mots \
-mapper wordcount_map.py -reducer wordcount_reduce.py \
-file wordcount_map.py -file wordcount_reduce.py
A noter :
- Si le fichier cible existe déjà, le supprimer : hadoop fs -rm -r jobsub/sample_data/nb_mots
- Pour obtenir de l’aide : hadoop jar /usr/hdp/2.2.4.2-2/hadoop-mapreduce/hadoop-streaming.jar -help
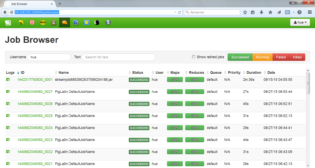
Vous pouvez suivre l’exécution des jobs à l’adresse https://192.168.239.128:8000/jobbrowser/ .
Enfin, pour afficher le résultat :
- hadoop fs -cat jobsub/sample_data/nb_mots/part-00000
Si vous voulez réaliser le même comptage avec un programme Java :
- hadoop jar hadoop-examples.jar wordcount jobsub/sample_data/midsummer.txt
jobsub/sample_data/nb_mots_java - hadoop fs -cat jobsub/sample_data/nb_mots_java/part-r-00000
Hive
Nous abandonnons maintenant les langages procéduraux pour passer aux outils de plus haut niveau.
Nous utiliserons pour cela l’interface Web fournie par Hortonworks
(pour rappel : https://192.168.239.128:8000/about/).
Commençons par Hive, qui fournit une interface de type SQL pour accéder aux données stockées dans HDFS.
Nous allons tout d’abord charger un fichier de données contenant des statistiques de baseball, qui nous servira pour Hive et Pig.
Un fichier zip peut être téléchargé ici : http://www.seanlahman.com/.
Le chargement dans HDFS se fait en cliquant sur l’icône File Browser de l’interface Web, puis Upload, Files, Select Files, choisir Batting.csv.
Nous allons maintenant manipuler les données du fichier batting à l’aide d’ordres Hive successifs saisis dans l’interface Beeswax (2e icône de l’interface Hortonworks).
On crée alors une table dans laquelle on stocke le nombre de runs par joueur et par année, puis on exécute des requêtes sur cette table :
- create table temp_batting (col_value STRING);
- LOAD DATA INPATH ‘/user/hue/Batting.csv’ OVERWRITE INTO TABLE temp_batting;
- create table batting (player_id STRING, year INT, runs INT);
- insert overwrite table batting
SELECT regexp_extract(col_value, ‘^(?:([^,]*)\,?){1}’, 1) player_id,
regexp_extract(col_value, ‘^(?:([^,]*)\,?){2}’, 1) year,
regexp_extract(col_value, ‘^(?:([^,]*)\,?){9}’, 1) run
from temp_batting;
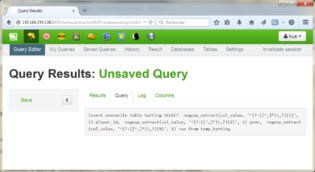
- SELECT year, max(runs) max_runs FROM batting GROUP BY year;
- SELECT a.year, a.player_id, a.runs from batting a
JOIN (SELECT year, max(runs) runs FROM batting GROUP BY year ) b
ON (a.year = b.year AND a.runs = b.runs)
SORT BY a.year ASC;
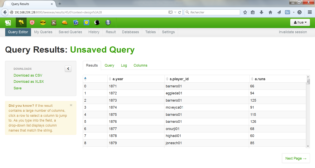
N.B. A chaque étape, Beeswax permet de visualiser les résultats, le contenu des tables et les logs d’exécution.
Pig
Pig est un langage de script de haut niveau utilisé avec Hadoop.
Il permet de réaliser des analyses de données sous forme de flux.
Nous allons maintenant manipuler les données du fichier batting à l’aide d’ordres successifs saisis dans l’interface Pig
(3e icône de l’interface Hortonworks).
Attention : ces requêtes doivent être exécutées ensemble, ce qui peut prendre une dizaine de minutes.
- — Chargement du fichier source
batting = LOAD ‘Batting.csv’ USING PigStorage(‘,’); - — Suppression de la ligne d’entête
raw_runs = FILTER batting BY $1>0; - — Création d’une table avec 3 colonnes
all_runs = FOREACH raw_runs GENERATE $0 AS playerID, $1 AS year, $8 AS runs; - — Regroupement par année
grp_data = GROUP all_runs BY (year); - — Création d’une table avec le nombre maximal de runs par année
max_runs_year = FOREACH grp_data GENERATE group as max_year, MAX(all_runs.runs) AS max_runs; - — Pour chaque année, recherche du joueur ayant le plus grand nombre de runs
join_max_runs = JOIN max_runs_year BY (max_year, max_runs), all_runs BY (year, runs); - — Extraction des colonnes 0, 2 et 4
join_data = FOREACH join_max_runs GENERATE $0 AS year, $2 AS playerID, $4 AS runs; - — Affichage d’un échantillon
limit_join_data = limit join_data 5;
describe join_data;
dump limit_join_data;
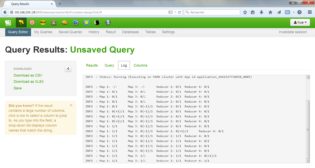
Ce qui donne le résultat final suivant :
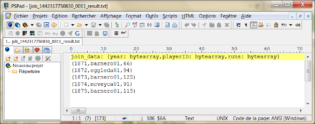
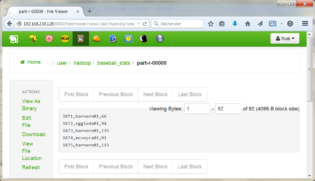
Si on veut conserver le résultat dans HDFS, il faut donc ajouter l’ordre suivant :
- STORE limit_join_data INTO ‘/user/hadoop/baseball_stats’ USING PigStorage (‘,’);
N.B. On peut également utiliser Pig à travers le Grunt shell (taper pig dans la fenêtre de commandes Windows) :
HCatalog
HCatalog est un outil permettant aux applications autres que Hive d’accéder à ses tables.
On peut ensuite charger directement les tables avec Pig ou MapReduce sans avoir à se soucier de redéfinir les schémas d’entrée ou de l’emplacement des données.
Ici, HCatalog puis Hive pourront alors être utilisés pour analyser des web logs.
On crée les tables omniturelogs, users et products à partir des fichiers tsv correspondants dans RefineDemoData.zip (https://s3.amazonaws.com/hw-sandbox/tutorial8/RefineDemoData.zip).
Pour cela, il suffit donc d’effectuer les manipulations suivantes dans l’interface web :
- Cliquer sur l’icône HCatalog de l’interface web,
- Ensuite, cliquer sur Create a new table from file,
- Puis : Choose a file, upload, create table (avec headers pour users et products, sans pour Omniture.0),
- Enfin Browse data pour visualiser le contenu des tables.
On crée une vue sur les logs dans Beeswax :
- CREATE VIEW omniture
AS SELECT col_2 ts, col_8 ip, col_13 url, col_14 swid, col_50 city, col_51 country, col_53 state
from omniturelogs
On crée ensuite une table globale pour analyser les données :
- create table webloganalytics
as select to_date(o.ts) logdate, o.url, o.ip, o.city, upper(o.state) state, o.country, p.category,
CAST(datediff(from_unixtime(unix_timestamp()), from_unixtime(unix_timestamp(u.birth_dt, ‘dd-MMM-yy’))) / 365 AS INT) age, u.gender_cd gender
from omniture o
inner join products p on o.url = p.url
left outer join users u on o.swid = concat(‘{‘, u.swid , ‘}’)
Finalement, on peut télécharger les résultats au format Excel :
Pour poursuivre dans votre apprentissage de Hadoop et son éco-système, rendez-vous sur notre page Tutoriels.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Commentaire (1)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
De ce que je vois, le traitement des données se fait par des successions de requêtes.
Ayant l'habitude de travailler avec la suite BI de SQL server et notamment SSIS, son ETL.
N'existe pas encore un ETL pour manipuler la donnée.
Merci par avance pour votre réponse