
La Business Intelligence (BI) traditionnelle est en train de rencontrer une mutation sans précédent, grâce à l’arrivée de la Data Science. En effet, jusqu’à présent, on concevait un tableau de bord avec des définitions d’indicateurs métiers définis de manière déterministe par l’homme.

S’assurer que ses indicateurs sont les bons
Qu’est-ce qui garantit qu’un indicateur est le bon ? parce que c’est l’indicateur qu’on utilise depuis des années sans se poser de questions ? Certainement pas !
Un jeu d’indicateurs doit en effet avoir un certain nombre de caractéristiques, comme :
- Couvrir l’ensemble des aspects d’une activité (on parle d’indicateurs endogènes et d’indicateurs exogènes) sans en omettre toutes les dimensions
- Les indicateurs doivent aussi être indépendants entre eux (on dit aussi orthogonaux)
Nous ne comptons plus les tableaux de bord mal construits contenant des indicateurs redondants, donc inutiles, ce qui ne garantit d’ailleurs nullement qu’ils couvrent tous les aspects métiers d’une activité. Ces tableaux de bord, finissent généralement ignorés par le plus grand nombre.
Or, ces deux caractéristiques sont précisément ce qu’on arrive à obtenir avec la Data Science grâce à des algorithmes factoriels. Les bases de données devenant de plus en plus exhaustives, et les traitements de l’information devenant de plus en plus matures, il est devenu urgent de penser à la Data Science avant d’implémenter de nouveaux indicateurs ou des tableaux de bord dans une activité.
Définition de la Data Science
On peut donner à la Data Science la définition pragmatique suivante :

Discipline cherchant à extraire de l’intelligence des données, dans le but de la rendre actionnable par les métiers, en s’appuyant principalement sur la Statistique, le Machine Learning et l’Intelligence artificielle (I.A.), et en utilisant des techniques qui ne sont pas accessibles ni par la Business Intelligence traditionnelle, la Dataviz ou l’exploration des données.
Quelles différences entre la Data Science et le Big Data ?
Avant d’aborder leurs différences, précisons d’abord que le Big Data et la Data Science font partie d’un ensemble cohérent.
Le Big Data apporte à l’entreprise la collecte et la mémorisation de l’information. La Data Science apporte, elle, l’agilité et l’intelligence (au sens anglo-saxon du terme).
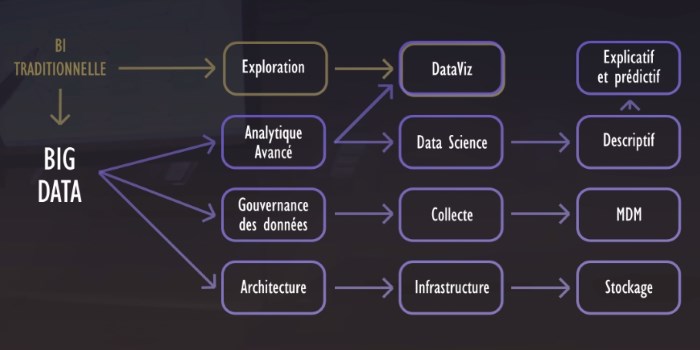
En outre, le Big Data va davantage se focaliser sur la collecte, le stockage et l’architecture des bases de données à mettre en place (notamment dans un Data Lake). La Data Science va quant à elle se concentrer sur le traitement des données, et la transformation de ces données en actions. Elle n’opère généralement pas directement sur le Data Lake, mais sur un support spécialisé et structuré (éventuellement hébergé dans le Data Lake). Ce support spécialisé et structuré s’appelle Data Hub.
Le Big Data n’augmente à lui-seul ni la maîtrise, ni l’intelligence contenue dans les données, seule la Data Science le peut. On peut aussi dire autrement que sans algorithmes, les données brutes ne sont que d’une piètre utilité. Il ne faut donc pas confondre données et connaissance, loin s’en faut. Le Big Data apporte les données, la Data Science la connaissance.
La Data Science est-elle vraiment une science nouvelle ?
Il est souvent fréquent d’entendre : « On n’a pas attendu le Big Data pour faire de la Data Science et des usages avancés tels que le Prédictif ». Cela sonne vrai, car les Statistiques sont répandues dans les entreprises depuis une trentaine d’années.
La majeure partie des algorithmes utilisés aujourd’hui ont été conçus dans les années 70, voire même encore plus tôt.
Les fondements de la Data Science restent donc les mêmes depuis 50 ans. En revanche, c’est dans la façon de conduire un projet et de l’exécuter que tout a changé.
Data Science : les nouvelles approches
Voici une liste non exhaustive de ce qui est nouveau en Data Science :
- La démocratisation de la discipline, notamment grâce à l’effet Buzz
- L’apport de nouvelles approches mixant statistiques et du machine learning
- L’apparition massive de nouveaux outils et langages (open sources, R et Python notamment)
- L’exploitation de nouvelles typologies et sources de données (données externes)
- Les Infrastructures Big Data (Hadoop, NoSQL, Cassandra, MongoDB, etc.), avec des capacités de stockage gigantesques
- Le Cloud accessible de partout
- La puissance de calcul des nouvelles technologies permet d’envisager de nouvelles applications
L’origine de la Data Science

Pour beaucoup, l’origine de la Data Science reste assez mystérieuse, ou obscure. Je trouve donc utile de rappeler d’où elle vient.
La Data Science vient avant tout du domaine de la Statistique, inventée par les Britanniques au début du 20ème siècle, par de brillants mathématiciens comme :
- Karl Pearson (1857 – 1936) , mathématicien britannique, il découvre les fondements mathématiques de la Statistique et notamment le coefficient de corrélation et le test du Khi2
- William Sealy Gosset dit « Student » (1876 – 1937), Britannique, il perfectionne les travaux de Pearson alors qu’il travaille pour les brasseries Guinness !
- Ronald Aylmer Fisher (1890 – 1962), biologiste britannique, il met Darwin en équation et pose les bases de la Statistique numérique
L’autre aspect de la Data Science, c’est le Machine Learning, ou l’intelligence artificielle, cette discipline plutôt américaine (ayant longtemps été concurrente de la Statistique). Là encore, on retrouve des noms comme :
- John von Neumann (1903 – 1957) Mathématicien et Physicien Américain, inventeur de l’ordinateur
- Alan Mathison Turing (1912 – 1954) Mathématicien Britannique, inventeur de la notion de programmation et d’algorithme
Bien sûr, ces listes ne sont pas exhaustives. La Data Science représente la discipline qui réunit (enfin) les deux filières.
On doit aussi, pour être juste, citer un dernier contributeur et non des moindres : Jean Paul Benzecri, né le 28 février 1932 (84 ans), statisticien français. Il est l’inventeur de fait de la statistique non numérique, grâce à des algorithmes comme l’Analyse factorielle des correspondances (AFC) et l’Analyse des correspondances multiples (ACM). Ces algorithmes constituent la première véritable pierre angulaire de l’unification entre Statistiques et machine learning.
Je vous invite, pour aller plus loin, à retrouver les éléments essentiels pour mener à bien votre projet dans mon article les 10 points clés pour réussir en Data Science.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Commentaire (1)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
De mon coté, j'ajoute l'effet localisation bien entendu avec l'apparition de la Géo_Bi dans les environnements bureautiques ou en ligne. La carte ou la représentation cartographique (moteur, corps humain, ...) synthétise le message et le rend "audible" pour le plus grand nombre ... Quand en plus elle permet de remonter de l'information et d'obtenir de nouvelles données ... Alors on est chez ARTICQUE ;-)
Et c'est pour cela qu'on est partenaire de B&D
A bientôt !