
Toutes les entreprises d’une certaine taille et avec une certaine ancienneté ont des données RH très simples par salarié du type ancienneté, temps de travail mensuel, salaire, résultats de la dernière évaluation, promotion lors des 5 dernières années, etc. Or, ces mêmes données peuvent aussi être valorisées d’une toute autre manière grâce au machine learning.

Les données RH : une source encore peu exploitée
Dans beaucoup d’entreprises, le département RH livre, grâce aux données dont ils disposent, des analyses descriptives et des tableaux de bords qui répondront à des questions simples comme :
- Quel est le salaire moyen dans le département Marketing ?
- Quelle est la distribution de l’ancienneté au sein du siège social ?
- Combien de personnes travaillent au sein de l’équipe Achats ?
Le machine learning permet d’aller encore plus loin. En effet, si on classifie ces données RH en fonction d’un résultat tel que « l’employé a quitté l’entreprise en 2016 », on entre dans le domaine prédictif. Cela permet au département des Ressources Humaines de comprendre non seulement les raisons du turnover parmi les salariés, mais aussi de prévoir ce qui va se passer dans les mois qui viennent, ceci avec une très bonne précision.
Les algorithmes de classification supervisée
Le modèle que nous devons concevoir est donc un modèle de classification supervisée, car nous voulons classer les employés selon leur risque de quitter l’entreprise. Un modèle de classification non supervisée (clustering) chercherait à classer les employés sans prendre en compte ce risque, mais en se basant simplement sur leurs similarités statistiques.
Dans le cas présent, nous souhaitons ainsi trouver les groupes de salariés plus ou moins enclins à démissionner prochainement.
A partir d’un fichier disponible sur le site Kaggle.com (voir encadré), nous allons comparer les performances de 9 algorithmes différents tels que les arbres de décision ou les machines à vecteur de support.
Nous avons sept variables prédictives par employé en plus du statut (toujours en poste ou pas) :
- Niveau de satisfaction
- Accident de travail
- Promotion lors des 5 dernières années
- Ancienneté dans la société
- Dernière évaluation
- Temps de travail mensuel moyen
- Nombre de projets effectués
Le point sur les principales méthodes de classification en Data Science
Avant d’explorer les résultats de chaque modèle, il est utile de faire le point sur les principales méthodes de classification utilisées en data science, de l’algorithme le plus ancien au plus récent.
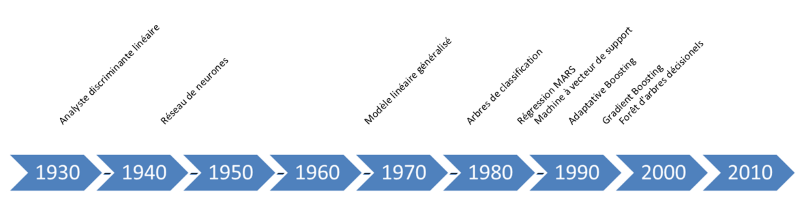
1. L’analyse discriminante linéaire (LDA) est une méthode relativement ancienne liée à l’analyse de variance et à l’analyse en composantes principales. C’est donc une méthode de réduction de la dimensionnalité des données qui extrait plusieurs composantes de corrélation minimale à partir de l’ensemble des données.
2. Le réseau de neurones (NNET) est une méthode inspirée schématiquement du fonctionnement des neurones biologiques. Néanmoins, elle est considérée comme une « boîte noire » tant elle reste compliquée à expliquer.
3. Le modèle linéaire généralisé (GLM) permet de construire un modèle linéaire avec des erreurs non normalement distribuées.
4. Les arbres de classification (CART), autrement appelés arbres de décision, permettent de représenter les données sous forme d’un arbre. Chaque extrémité (ou branches) de celui-ci est une combinaison unique des variables de la base.
5. La régression spline (MARS) est une forme de modèle de régression avec ajout de fonctions charnières pour prendre en compte localement des non-linéarités .
6. La machine à vecteurs de support (SVM) est dérivée d’autres méthodes comme la régression logistique ou l’analyse discriminante linéaire. Cette dernière consiste à chercher une frontière de séparation de distance maximale avec les échantillons les plus proches (appelés vecteurs supports).
7. L’adaptive boosting (ADA) est une des plus anciennes méthodes de boosting. L’idée est de créer une prédiction qui performe bien en agrégeant un ensemble de prédicteurs « faibles » (ici des arbres de décision).
8. Le gradient boosting (XGB) est une autre méthode de boosting plus récente, très utilisée dans les compétitions de Data Science.
9. Les forêts d’arbres décisionnels (RF) consistent en un échantillonnage multiple de sous arbres de classification, au niveau des variables aussi bien que des observations.
Déroulement de la classification
La première étape d’une classification consiste à explorer et préparer les données, en examinant tout d’abord la distribution des variables et les corrélations entre variables. Nous ne rentrerons pas dans le détail et assumerons que notre jeu de données RH obéit aux hypothèses fondamentales préalables à une bonne classification.
Afin de construire chacun des modèles et ensuite tester leur performance, il est commun de séparer le jeu de données en 2 avec 75% pour la construction et 25% pour le test. Dans notre cas, il est important de conserver la même proportion de personnes ayant quitté l’entreprise dans les 2 échantillons, en l’occurrence 24%.
Nous nous assurerons d’obtenir les meilleurs modèles en opérant ce que l’on appelle une « cross-validation ». Cela qui consiste à construire les modèles à partir de sous-échantillons aléatoires et de les tester à chaque fois afin d’obtenir le meilleur paramétrage pour chacun. Dans notre étude nous allons faire 10 tirages aléatoires.
Estimation de la performance des modèles
Il existe plusieurs façons d’estimer la performance d’un modèle, telles que :
- La précision : le modèle a fait une prédiction correcte
- La spécificité : le modèle a correctement prédit les cas où l’événement ne s’est pas produit
- La sensibilité : le modèle a correctement prédit les cas où l’événement s’est produit
Les graphiques ci-dessous donnent les moyennes de ces mesures par modèle :
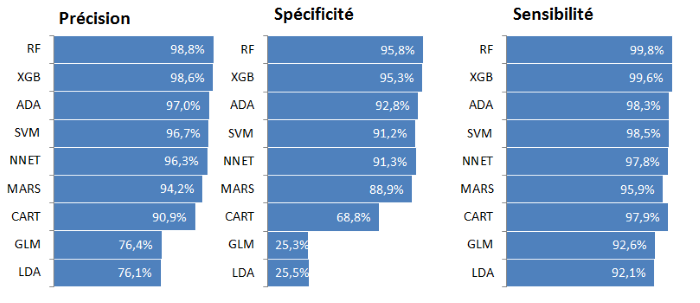
Nous voyons clairement que les Random Forest et Gradient Boosting performent le mieux. A contrario, les analyses discriminantes et les modèles linéaires généralisés font piètre figure.
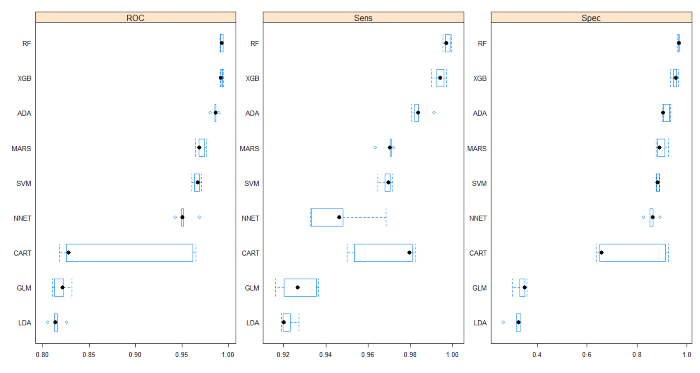
Par ailleurs, quand la question du choix d’un unique modèle final se pose, il est utile de comparer les distributions de ces mesures de performance. Ceci peut alors être fait à l’aide des résultats de « cross-validation », où nous avons 10 mesures de sensibilité et de spécificité pour chaque modèle.
Les graphiques ci-dessous montrent de gauche à droite le minimum, le 1er quartile, la médiane, le 3ème quartile et le maximum. Ils permettent de valider :
- la supériorité des RF sur le XGB dans notre cas, avec des distributions bien plus resserrées autour de la médiane pour RF que XGB, ce qui assure une meilleure stabilité du modèle.
- le caractère trop aléatoire des résultats issus d’arbres aléatoires simples (type CART).
- le gros problème de faible spécificité des modèles LDA er GLM.
Ce que l’on peut en conclure
1. Nous avons montré que 99% des cas sont correctement prédits.
Trop beau pour être vrai ? Sans doute. En effet, les données RH peuvent différer entre entreprises en raison de problèmes de cohérence des mesures ou tout simplement de moyens humains pour les traiter. Cette étude a pour but d’illustrer la théorie par l’exemple, mais dans un cas ou l’application est facilement déployable.
En admettant que ce pourcentage soit inférieur, il reste cependant une grande marge permettant d’améliorer la gestion RH dans tous les cas.
2. Le même type d’analyse peut s’appliquer à tout problème où l’on cherche à prédire un événement simple :
Mon client va-t-il résilier son contrat le mois prochain ? Ce nouveau client est-il potentiellement un fraudeur ? Lesquels de mes clients auront le plus envie d’acheter mon nouveau produit ? Un patient va-t-il souffrir d’effets secondaires si je lui administre tel ou tel médicament ? etc.
3. Nous avons vu que les algorithmes de classification les plus récents sont les plus précis.
Chaque compagnie qui voudra appliquer un de ces modèles va choisir le mieux adapté à son environnement, selon le volume des données et le marché cible. Certaines compagnies se contenteront ainsi d’algorithmes moins précis mais plus rapides et mieux interprétables. D’autres seront en revanche prêtes à investir en puissance de calcul afin d’obtenir une précision maximale.
Il faut donc placer le curseur au cas par cas en fonction du but recherché, des moyens disponibles et de l’aversion au risque.
Vous souhaitez en savoir plus sur l’utilisation du Machine Learning ? Business & Decision est là pour vous accompagner. N’hésitez pas à nous contacter.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Commentaire (1)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.