Plus de 20 ans d’expérience dans la mise en place d’architectures dédiées à la valorisation de vos données grâce aux technologies BI et Big Data.
Tous les articles de Stéphane WALTER
TUTORIEL | Spark Structured Streaming : les tests de performance
Spark est un framework open source de calcul distribué. Plus performant qu'hadoop, disponible avec trois langages principaux (Scala, Java, Python), il s'est rapidement taillé une place de choix au sein...

TUTORIEL | Spark Structured Streaming : de la transformation des données aux tests unitaires
Spark est un framework open source de calcul distribué. Plus performant qu'Hadoop, disponible avec trois langages principaux (Scala, Java, Python), il s'est rapidement taillé une place de choix au sein...

TUTORIEL | Spark Structured Streaming : de la gestion des données à la maintenance des traitements
Spark est un framework open source de calcul distribué. Plus performant qu'Hadoop, disponible avec trois langages principaux (Scala, Java, Python), il s'est rapidement taillé une place de choix au sein...

DataOps : conseils pour spécifier et documenter les données d’un projet Big Data
L'exploitation de tout le potentiel de vos projets Big Data nécessite une bonne documentation de vos données. Les principes DataOps favorise la mise en place d'une démarche appropriée, essentielle pour...

TUTORIEL | MongoDB : les possibilités d'agrégation
Pour ce quatrième et dernier volet de notre série de tutoriels pour vous faire découvrir MongoDB. Nous abordons aujourd'hui les possibilités d'agrégation.

TUTORIEL | MongoDB : Indexation et performance
Suite de notre série d'articles pour vous faire découvrir MongoDB. Pour ce troisième tutoriel, nous allons examiner les mécanismes d’indexation et le suivi de performance.

TUTORIEL | MongoDB : Insérer, supprimer et mettre à jour des documents
Afin de vous faire découvrir MongoDB, je vous propose une série d’articles. Je vous propose d'aborder pour ce deuxième tutoriel les fonctions d’insertion, de suppression et d'update.

TUTORIEL | MongoDB : examiner les fonctionnalités de requêtage
Vous allez découvrir ici MongoDB à travers une série de tutoriels. Nous allons aborder aujourd'hui l’installation et examiner les fonctionnalités de requêtage de la solution. MongoDB est une base de...

TUTORIEL | Comment créer une machine MongoDB avec Vagrant ?
Vagrant est un logiciel permettant d'automatiser la création de machines virtuelles. Par défaut, Vagrant utilise Virtualbox mais il est possible de déployer les machines virtuelles sur d'autres fournisseurs comme VMWare,...

TUTORIEL | Premiers pas avec Zeppelin
Zeppelin est le compagnon idéal de toute installation Spark. Ce notebook permet de faire des analyses interactives au travers d’un navigateur web. Zeppelin permet d’exécuter du code Spark et de...

Il était une fois le SQL sous Hadoop - 1 an après
Dans l'article Il était une fois le SQL sous Hadoop, je décrivais le foisonnement de solutions existantes pour travailler en SQL dans le Big Data. Plus d'un an s'est écoulé....

Miss France : quelle miss aurait été élue sur Twitter ?
L’élection Miss France génère nombre de commentaires sur les réseaux sociaux, notamment sur Twitter. Ces contenus offre de nombreuses possibilités d'analyse pour répondre à la question : « Quelle Miss...

5 raisons de choisir Spark pour les traitements de vos Big Data
Rapide, efficace, riche, adaptable… Spark a le vent en poupe pour tout ce qui concerne les traitements Big Data ! Voici 5 bonnes raisons pour lesquelles ce système de traitement...

Faut-il tomber amoureux de MongoDB ?
A l'occasion d'un projet d'analyse des logs de web services réalisé pour un client, nous avons été amené à tester MongoDB... et j'avoue que je suis tombé sous le charme de...
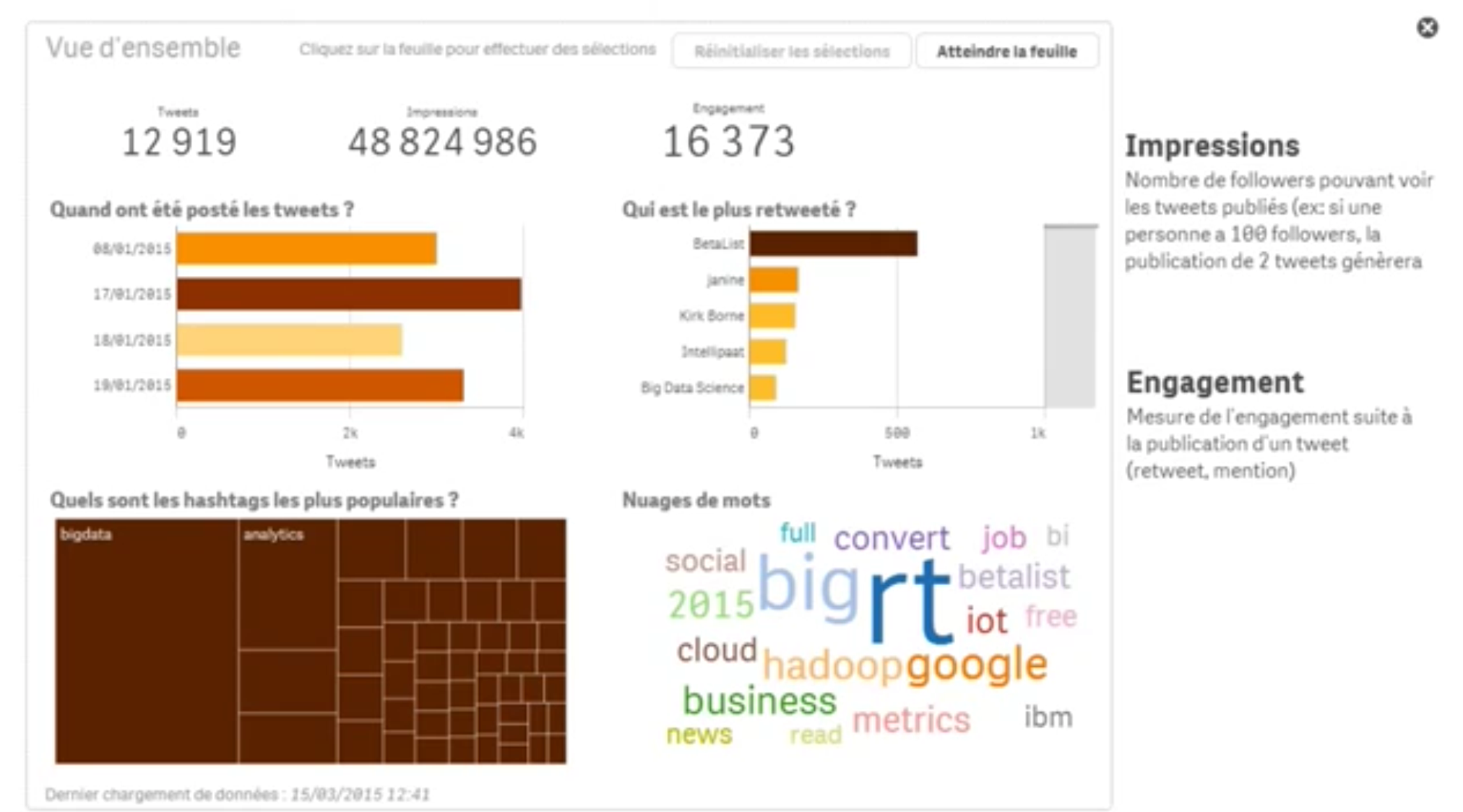
TUTORIEL | Tutoriel: visualiser les données twitter avec Qlik Sense
Après avoir vu dans l'article précédent comment récupérer les données Twitter avec Flume et Hive, j'ai voulu aller jusqu'à la visualisation des données. Pour se faire, j'ai utilisé Hive pour calculer quelques...

TUTORIEL | Analyser les données Twitter avec Flume et Hive
L'objectif de ce tutoriel est de vous montrer comment utiliser Flume et Hive pour analyser des données en provenance de Twitter. Il a également pour objectif de mettre en évidence...

Il était une fois dans le SQL sous Hadoop
Si MapReduce s'impose pour traiter de grands volumes de données en mode batch, si Storm apparait comme le meilleur moteur d'intégration temps-réel, les choses sont beaucoup moins claires dans le domaine de l'analyse de...

TUTORIEL | Installer soi-même un cluster Hadoop (1 nœud)
Vous avez sûrement lu de nombreux articles sur Hadoop et vous souhaitez maintenant vous familiariser avec. Mais comment faire pour apprivoiser cette nouvelle technologie ? L'approche recommandée consiste à installer une machine...

Trois tutoriels pour démarrer avec Hadoop
On trouve énormément d'articles sur le Big Data mais il est parfois frustrant de n'aborder que les concepts. Certaines personnes, comme moi, ont besoin de visualiser les outils pour appréhender...

Les solutions technologiques du Big Data
Cet article présente les solutions technologiques du Big Data. C'est le troisième d'une série de trois sur le thème "De la BI au Big Data".
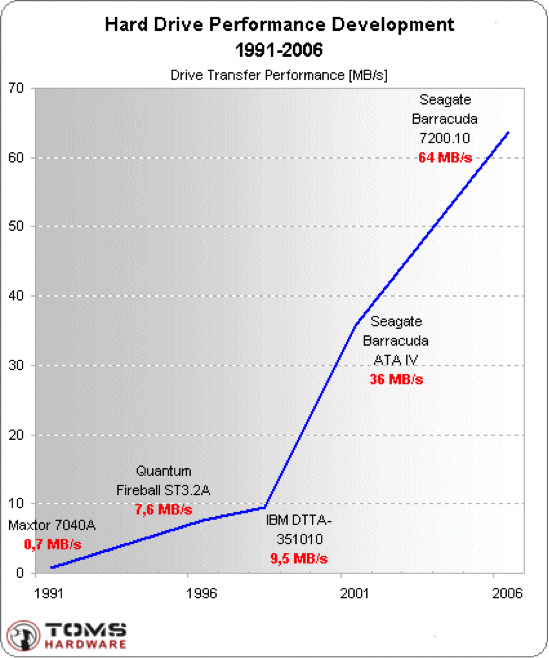
Le Big Data repousse les limites de la loi de Moore
Le Big Data apparaît aujourd'hui comme une continuité logique et une évolution naturelle du décisionnel. Après avoir rappelé dans le précédent article les fondamentaux de la BI, cet article se propose de faire un...

Les fondamentaux de la Business Intelligence
Le Big Data apparaît aujourd'hui comme une continuité logique et une évolution naturelle du décisionnel. Cet article se propose de faire un retour sur les fondamentaux de la Business Intelligence et ce qui a...